
¿Sabías que hay un archivo diminuto que puede marcar si Google te rastrea o te ignora por completo?
No, no es ciencia ficción ni una conspiración de Silicon Valley. Se llama robots.txt y aunque suene como el nombre de un personaje secundario de Star Wars, en realidad es el portero invisible de tu web.
Y como buen portero, puede dejar pasar a quien le caiga bien… o cerrar la puerta en toda la cara de Google. Literalmente.
Vamos a destriparlo sin tecnicismos innecesarios y con ejemplos para que puedas configurarlo como un ninja del SEO. Y, por supuesto, con referencias a la documentación oficial de Google para que no digas que nos lo estamos inventando.
¿Qué es robots.txt y por qué deberías preocuparte?
Antes de tirarte al barro, tienes que saber qué tienes entre manos. robots.txt es un archivo de texto plano ubicado en la raíz de tu web que indica a los bots de los motores de búsqueda qué partes de tu sitio pueden rastrear y cuáles deben evitar.
Sí, es como el semáforo de tu web: verde para algunas URLs, rojo para otras.
Pero no te confundas: no es para ocultar contenido confidencial. Para eso, mejor usa contraseñas o el tag noindex.
Ejemplo real:
User-agent: *
Disallow: /admin/
Esto le dice a todos los bots que no entren en la carpeta /admin/. Simple y directo, como debe ser.
Importante: Bloquear algo con robots.txt no lo elimina de Google. Solo evita que se rastree. Si quieres desindexar, necesitarás un noindex en el HTML o en las cabeceras. Google lo deja clarito aquí: Documentación oficial.
Cómo crear y configurar tu archivo robots.txt
Esta parte es la chicha. Aquí es donde pasas de aprendiz de SEO a jedi del rastreo. Vamos paso a paso.
Paso 1: Dónde va
Tiene que estar en la raíz de tu dominio. Es decir:
https://tusitio.com/robots.txt
Ni en subcarpetas, ni disfrazado. Google lo busca ahí. Y punto.
Más info: Ubicación correcta del archivo.
Paso 2: Sintaxis básica
Este archivo se compone de directivas simples. Aquí tienes una tabla resumen:
| Directiva | ¿Qué hace? |
|---|---|
| User-agent | Especifica a qué bot se aplica la regla |
| Disallow | Indica rutas que no deben rastrearse |
| Allow | Permite rastrear rutas dentro de una carpeta bloqueada |
| Sitemap | Proporciona la URL del sitemap para facilitar la indexación |
| Crawl-delay* | Establece un tiempo de espera entre peticiones (no siempre soportado) |
Ejemplo funcional:
User-agent: *Disallow: /carpeta-bloqueada/Allow: /carpeta-bloqueada/imagen.jpg
Sitemap: https://tusitio.com/sitemap.xml
User-agents más conocidos
Cada bot tiene su propio nombre, así que si quieres dar órdenes personalizadas, aquí tienes algunos de los más habituales:
| User-agent | Descripción |
| Googlebot | Bot de Google para resultados web |
| Googlebot-Image | Bot de imágenes de Google |
| Googlebot-News | Bot de Google News |
| Bingbot | Bot del buscador Bing |
| Slurp | Bot de Yahoo |
| DuckDuckBot | Bot de DuckDuckGo |
| Baiduspider | Bot del buscador Baidu (China) |
| Yandex | Bot del buscador ruso Yandex |
| AhrefsBot | Bot del rastreador de Ahrefs |
| SemrushBot | Bot del rastreador de Semrush |
Ejemplo:
User-agent: Googlebot-ImageDisallow: /imagenes-privadas/
Este ejemplo bloquea solo a Google Imágenes en esa carpeta.
Más info sobre user-agents: Listado oficial de bots de Google.
Paso 3: Cuidado con los comodines
Los comodines pueden ayudarte o meterte en líos. Vamos con calma:
- * = cualquier cadena de caracteres
- $ = final de la URL
Buenas prácticas y trampas comunes
Aquí van unos consejos que te evitarán sudores fríos y URLs desaparecidas misteriosamente.
- No bloquees CSS ni JS: Google necesita ver tu web completa. Si lo bloqueas, no entiende bien la estructura.
- Evita sobreoptimizar: No bloquees por bloquear. Cada regla debería tener un porqué.
- Actualiza y prueba tu archivo: Usa Search Console para verificar que no estás bloqueando contenido vital.
- Incluye siempre tu sitemap: Ayuda a los bots a entender qué quieres que encuentren.
- Haz pruebas: Antes de subir tu robots.txt pruébalo que luego, que luego pasan cosas
Enlace útil: Prueba tu robots.txt con los amigos de technicalseo.com
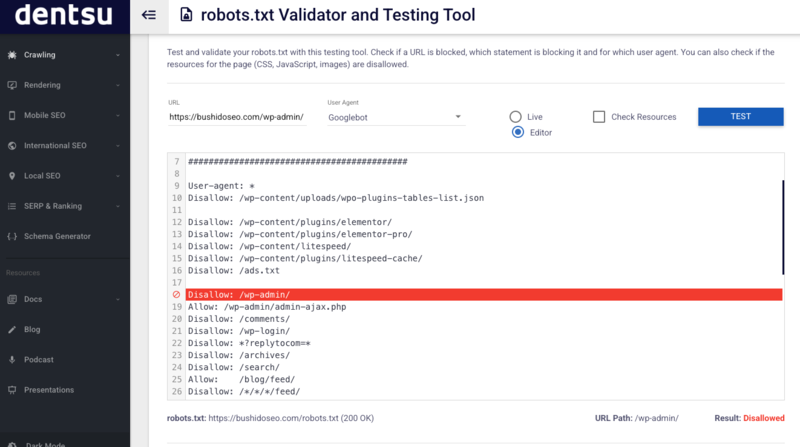
Ejemplos de robots.txt para WordPress y otras páginas
No todos los CMS funcionan igual. Aquí te dejamos lo esencial para los más usados.
WordPress
WordPress crea un archivo virtual si no existe uno real. El básico se ve así:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Pero si quieres control total, mejor crear uno propio o editarlo con plugins como Yoast SEO.
Ejemplo recomendado:
User-agent: *
Disallow: /wp-content/plugins/
Allow: /wp-content/uploads/
Sitemap: https://tusitio.com/sitemap_index.xml
Ejemplo de robots.txt para un eCommerce
En una tienda online, el archivo robots.txt puede marcar la diferencia entre una buena indexación de productos o un caos de URLs duplicadas, filtros indexados y contenido sin sentido en los resultados de búsqueda.
User-agent: *
Disallow: /carrito/
Disallow: /checkout/
Disallow: /cuenta/
Disallow: /buscar/
Allow: /productos/
Sitemap: https://tutienda.com/sitemap.xml
Este ejemplo bloquea las secciones sensibles o que no aportan valor SEO (como el carrito o la cuenta del usuario), pero permite el rastreo de productos. Fundamental para que Google vea lo que realmente quieres vender.
Conclusión
El robots.txt es pequeño, sí. Pero poderoso. Como el picante: un poco da sabor, demasiado… quema.
Úsalo con cabeza, revisa tus directivas y no bloquees sin razón. Y sobre todo, prueba antes de publicar. Porque en SEO, más vale prevenir que llorar rankings perdidos.
¿Te animas a revisar el tuyo hoy mismo?